

Blog Category
 Mobile App Testing(136)
Mobile App Testing(136) Web App Testing(11)
Web App Testing(11) Game Testing(24)
Game Testing(24)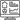 Automation Testing(73)
Automation Testing(73) Security Testing(32)
Security Testing(32) Performance Testing(15)
Performance Testing(15) Selenium(32)
Selenium(32) Test Management(15)
Test Management(15) Usability Testing(24)
Usability Testing(24) Guides and Tutorials(99)
Guides and Tutorials(99) Best Practices(28)
Best Practices(28) Expert Insights(20)
Expert Insights(20) Software Testing Events(4)
Software Testing Events(4)
Our Services
- App Testing(136)
- Web App Testing(11)
- Game Testing(24)
- Automation Testing(79)
 Load Testing(9)
Load Testing(9)- Security Testing(32)
 Performance Testing(15)
Performance Testing(15) Hire a Tester(71)
Hire a Tester(71)
Our Careers

What is Data Lake? Architecture and Importance
March 16th, 2020
A data lake is a collection of raw data in the form of blobs or files. It acts as a single store for all the data in an enterprise that can include raw source data, pictorial representations, charts, processed data, and much more.
An advantage with the data lake is that it can contain different forms of data including structure data like a database including rows and columns, semi-structured data in the form of CSV, XML, JSON, etc.
It can also store unstructured data like PDF, emails, and word documents along with images, and videos.
It is a store of all the data and information in an enterprise. The concept of the data lake is catching up fast due to the growing needs of data storage and analysis in all the domains.
 Let us learn more data lakes.
What is Data Lake?
We need to understand what a data mart First for the answer. Datamart can be considered as a repository of summarized data for easy understanding and analysis.
Pentaho CTO James Dixon was the person who first used the term As per him, a data mart is like packaged and cleaned drinking water that is ready for consumption.
The source of this drinking water is the lake. Hence the term data lake. A storehouse of information from where the data mart can interpret and filter out the data as needed.
Let us learn more data lakes.
What is Data Lake?
We need to understand what a data mart First for the answer. Datamart can be considered as a repository of summarized data for easy understanding and analysis.
Pentaho CTO James Dixon was the person who first used the term As per him, a data mart is like packaged and cleaned drinking water that is ready for consumption.
The source of this drinking water is the lake. Hence the term data lake. A storehouse of information from where the data mart can interpret and filter out the data as needed.
 What is the importance of the data lake?
it's a huge storage of raw data. This data can be used in infinite ways to help people in varied positions and roles.
Data is information and power, that can be used to arrive at inferences and help in decision making too.
What is data ingestion?
Data Ingestion
Data Ingestion; what does it does? So well, it permits the connectors to source the data from various data sources and piles them up into the Lake.
What all does Data Ingestion supports?
It supports Structured, Semi-Structured, and Unstructured data. Batch, Real-Time, One-time load, and similar multiple ingestions. Databases, Webservers, Emails, IoT, FTP, and many such data sources.
What is Data Governance
Data governance is an important activity in a data lake that supports the management of availability, usability, integrity, and security of the organizational data.
Factors that are important in Data Lake
Security
Security of data is a must, be it in any kind of data storage, so is true for the data lake. Every layer of the Data Lake should have proper security implemented. Though the main purpose of security is to bar unauthorized users, at the same time it should support various tools that permit you to access data with ease.
Some key features of data lake security are:
What is the importance of the data lake?
it's a huge storage of raw data. This data can be used in infinite ways to help people in varied positions and roles.
Data is information and power, that can be used to arrive at inferences and help in decision making too.
What is data ingestion?
Data Ingestion
Data Ingestion; what does it does? So well, it permits the connectors to source the data from various data sources and piles them up into the Lake.
What all does Data Ingestion supports?
It supports Structured, Semi-Structured, and Unstructured data. Batch, Real-Time, One-time load, and similar multiple ingestions. Databases, Webservers, Emails, IoT, FTP, and many such data sources.
What is Data Governance
Data governance is an important activity in a data lake that supports the management of availability, usability, integrity, and security of the organizational data.
Factors that are important in Data Lake
Security
Security of data is a must, be it in any kind of data storage, so is true for the data lake. Every layer of the Data Lake should have proper security implemented. Though the main purpose of security is to bar unauthorized users, at the same time it should support various tools that permit you to access data with ease.
Some key features of data lake security are:
 What are the maturity stages of a data lake?
Data Lake maturity Stages
There are different maturity stages of a data lake and their understanding might differ from person to person, but the basic essence remains the same.
Stage 1: in the very first stage the focus is on enhancing the capability of transforming and analyzing data based on business requirements. The businesses find appropriate tools based on their skill set to obtain more data and build analytical applications.
Stage 2: in stage two businesses combine the power of their enterprise data warehouse and the data lake. These both are used together.
Stage 3: in the third stage the motive is to extract as much data as they can. Both enterprise data warehouses and data lake work in unison and play their respective roles in business analytics.
Stage 4: Enterprise capability like Adoption of information lifecycle management capabilities, information governance, and Metadata management is added to the data lake. Only a few businesses reach this stage.
Here are some major areas where data lakes are most helpful:
What are the maturity stages of a data lake?
Data Lake maturity Stages
There are different maturity stages of a data lake and their understanding might differ from person to person, but the basic essence remains the same.
Stage 1: in the very first stage the focus is on enhancing the capability of transforming and analyzing data based on business requirements. The businesses find appropriate tools based on their skill set to obtain more data and build analytical applications.
Stage 2: in stage two businesses combine the power of their enterprise data warehouse and the data lake. These both are used together.
Stage 3: in the third stage the motive is to extract as much data as they can. Both enterprise data warehouses and data lake work in unison and play their respective roles in business analytics.
Stage 4: Enterprise capability like Adoption of information lifecycle management capabilities, information governance, and Metadata management is added to the data lake. Only a few businesses reach this stage.
Here are some major areas where data lakes are most helpful:
 What's the architecture of a Data lake?
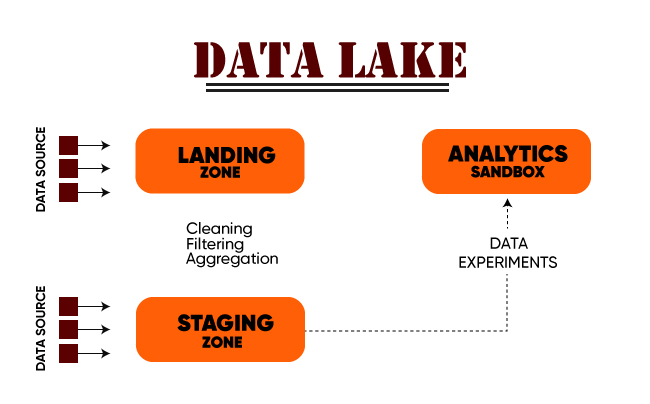
The above image is a pictorial representation of the architecture of the data lake.
ingestion tier - Contains data source. Data is fed to the data lake in batches and that too in real-time
Insights tier - Located on the right side, is the insights of the system.
HDFS - Spcialy built a cost-effective system for structured and unstructured data.
Distillation - Data will be retrieved from storage and will be converted to structured data
Processing - User queries will be run through analytical algorithms to generate structured data
Unified operations - system management, data management, monitoring, workflow management, etc.
What's the architecture of a Data lake?
The above image is a pictorial representation of the architecture of the data lake.
ingestion tier - Contains data source. Data is fed to the data lake in batches and that too in real-time
Insights tier - Located on the right side, is the insights of the system.
HDFS - Spcialy built a cost-effective system for structured and unstructured data.
Distillation - Data will be retrieved from storage and will be converted to structured data
Processing - User queries will be run through analytical algorithms to generate structured data
Unified operations - system management, data management, monitoring, workflow management, etc.
 Differences between data lake, database, and data warehouse
In the simplest form data lake contains structured and unstructured data while both database and data warehouse except pre-processed data only. Here are some differences between all of them.
Differences between data lake, database, and data warehouse
In the simplest form data lake contains structured and unstructured data while both database and data warehouse except pre-processed data only. Here are some differences between all of them.
Data Lake Implementation
Data Lake is a heterogeneous collection of data from various sources. There are two parts to any successful implementation of a data lake.
The first part is the source of data. Since the lakes take all forms of data, the source need not have any restriction. This can be the company's production data to be monitored, emails, reports, and more.
 Best practices for Data Lake Implementation:
Best practices for Data Lake Implementation:
 What are the Challenges of building a Data Lake:
Some of the common challenges of Data Lake are:
What are the Challenges of building a Data Lake:
Some of the common challenges of Data Lake are:
Let us learn more data lakes.
What is Data Lake?
We need to understand what a data mart First for the answer. Datamart can be considered as a repository of summarized data for easy understanding and analysis.
Pentaho CTO James Dixon was the person who first used the term As per him, a data mart is like packaged and cleaned drinking water that is ready for consumption.
The source of this drinking water is the lake. Hence the term data lake. A storehouse of information from where the data mart can interpret and filter out the data as needed.
What is the importance of the data lake?
it's a huge storage of raw data. This data can be used in infinite ways to help people in varied positions and roles.
Data is information and power, that can be used to arrive at inferences and help in decision making too.
What is data ingestion?
Data Ingestion
Data Ingestion; what does it does? So well, it permits the connectors to source the data from various data sources and piles them up into the Lake.
What all does Data Ingestion supports?
It supports Structured, Semi-Structured, and Unstructured data. Batch, Real-Time, One-time load, and similar multiple ingestions. Databases, Webservers, Emails, IoT, FTP, and many such data sources.
What is Data Governance
Data governance is an important activity in a data lake that supports the management of availability, usability, integrity, and security of the organizational data.
Factors that are important in Data Lake
Security
Security of data is a must, be it in any kind of data storage, so is true for the data lake. Every layer of the Data Lake should have proper security implemented. Though the main purpose of security is to bar unauthorized users, at the same time it should support various tools that permit you to access data with ease.
Some key features of data lake security are:
- Accounting,
- Authentication
- Data Protection
- Authorization
- Tracking changes
- Capturing who/when and how the data changes.
What are the maturity stages of a data lake?
Data Lake maturity Stages
There are different maturity stages of a data lake and their understanding might differ from person to person, but the basic essence remains the same.
Stage 1: in the very first stage the focus is on enhancing the capability of transforming and analyzing data based on business requirements. The businesses find appropriate tools based on their skill set to obtain more data and build analytical applications.
Stage 2: in stage two businesses combine the power of their enterprise data warehouse and the data lake. These both are used together.
Stage 3: in the third stage the motive is to extract as much data as they can. Both enterprise data warehouses and data lake work in unison and play their respective roles in business analytics.
Stage 4: Enterprise capability like Adoption of information lifecycle management capabilities, information governance, and Metadata management is added to the data lake. Only a few businesses reach this stage.
Here are some major areas where data lakes are most helpful:
- Marketing operations: the data related to consumer buying patterns, consumer purchasing power, product usage, frequency of buying, and more are critical inputs for the marketing operations team. Data lakes help in getting this data within no time.
- Product Managers: Managers need data to ensure the product delivery is on track, check the resource allocation and their utilization, their billing, and more. Data lakes help them in getting this data instantaneously and at the same place.
- Sales Operations: while marketing teams use the data to design their marketing plans, the sales team uses a similar set of data to understand more about the sales pattern and target the consumers accordingly.
- Analysts and data architects: For analyst and architects’ data is there bread and butter, they need data in all forms. They analyze and interpret data from multiple sources in several ways to derive inferences for management and leadership teams.
- Product Support: Every product once it is rolled out to the consumers will undergo several changes as per the usage patterns. These are taken care of by the product support teams. The long-term data of the enhancements requested and the features most used, the team may decide to roll out more similar or additional features.
- Customer Support: The teams handling customer support divisions may come across several issues and resolutions day-in and day-out. These issues may get repeated over the months, years and even decades. A consolidated data of these issues and resolutions are very helpful to the executives when they reoccur.
- One of the biggest advantages of a data lake is that it can derive reports and data by processing innumerable raw data types.
- It can be used to save both structured and unstructured data like excel sheets and emails. And both these data points can be used for deriving the analysis.
- It is a store of raw data that can be manipulated multiple times in multiple ways as per the needs of the user.
- There are several different ways in which one can derive the needed information. There can hundreds and thousands of different queries that can be used to retrieve the information needed by the user.
- Low cost is another advantage of most of the new technologies that are coming up. They aim to maximize efficiency and reduce costs. This is true for data lakes as well. They provide a low cost, single point storage solution for a company’s data needs.
What's the architecture of a Data lake?
The above image is a pictorial representation of the architecture of the data lake.
ingestion tier - Contains data source. Data is fed to the data lake in batches and that too in real-time
Insights tier - Located on the right side, is the insights of the system.
HDFS - Spcialy built a cost-effective system for structured and unstructured data.
Distillation - Data will be retrieved from storage and will be converted to structured data
Processing - User queries will be run through analytical algorithms to generate structured data
Unified operations - system management, data management, monitoring, workflow management, etc.
Differences between data lake, database, and data warehouse
In the simplest form data lake contains structured and unstructured data while both database and data warehouse except pre-processed data only. Here are some differences between all of them.
- Type of Data: As mentioned above, both the database and the data warehouse need the data to be in some structured format to save. A data lake, on the other hand, can contain and interpret all types of data including structured, semi-structured and even unstructured.
- Pre-processing: the data in a data warehouse needs to be pre-processed using schema-on-write for the data to be useful for storage and analysis. Similarly, in a database also indexing needs to be done. In the case of a data lake, however, no such pre-processing is needed. It takes data in the raw form and stores for use at a later stage. It is more like post-processing, where the processing happens when the data is requested by the user.
- Storage Cost: The cost of storage for a database would vary based on the volume of data. A database can be used for small and large amounts of data inputs and accordingly the cost would change. But for when it comes to a data warehouse and data lakes, we are talking about bulk data. In this case, with new technologies like big data and Hadoop coming into picture data lakes do come forth as a cheaper storage option as compared to a data warehouse.
- Data Security: Data warehouse has been there for quite some time now. Any security leaks are already plugged. But that is not the case with new technologies like data lakes and big data. They are still prone breaches, but they will eventually stabilize to a strong and secure data storage option soon.
- Usage: A database can be used by everyone. A simple data stored in your excel sheet can also be considered as a database. It has universal acceptance. A data warehouse, on the other hand, is used mostly by big business establishments with a huge amount of data to be stored. While data lakes are most used for scientific data analysis and interpretation.
| Data Lake | Data Warehouse |
| Stores everything | Stores only business-related data |
| Lesser control | Better control |
| Can be structured, unstructured and semi-structured | In tabular form and structure |
| Can be a data source to EDW | Compliments EDW |
| Can be used in analytics for the betterment of business | Mainly used for data retrieval |
| Used by scientists | Used by business professionals |
| Low-cost storage | expensive |
- Landing Zone: This is the place where the data first enters the data lake. This is mainly the unstructured and unfiltered data. A certain amount of filtering and tagging happens here. For example, if there are some values that are abnormally high when compared to others, these may be tagged as error-prone and discarded.
- Staging Zone: There can be two inputs to the staging zone. One is the filtered data from the landing zone and the second is direct from a source that does not need any filtering. Reviews and comments from the end-users are one example of this type of data.
- Analytics Sandbox: this is the place where the analysis is done using algorithms, formulae, etc. to bring up charts, relative numbers, and probability analysis as and when needed by the organization.
Best practices for Data Lake Implementation:
- Availability should form the basis of the Designing of Data Lake instead of what is required.
- The native data type should be supported by Architectural components, their interaction, and identified products.
- It should support customized management
- Do not define schema and data requirement until queried for disposable components integrated with service API forms the base for designing.
- Attune Data Lake architecture to the specific industry. Ensure that the necessary capabilities are already a part of the design. New data should be quickly on-boarding
- It should also support present enterprise data management techniques and methods
- Independently manage Data ingestion, discovery, administration, transformation, storage, quality, and visualization
What are the Challenges of building a Data Lake:
Some of the common challenges of Data Lake are:
- Data volume is higher in the data lake, so the process has to be dependent on programmatic administration
- Sparse, incomplete, volatile data is difficult to deal with.
- Wider scope of the dataset
- Larger data governance & support for the source
- A risk involving designing of Data Lake
- Data Lake might lose its relevance and momentum after some time.
- Higher storage & compute costs
- Security and access control.
- Unstructured Data may lead to unprecedented Chaos, data wastage, Disparate & Complex Tools, Enterprise-Wide Collaboration,
- No insights from others who have worked with the data
- Business intelligence software built by Sisense that can be used for data-driven decision making
- Depop , a peer to peer social shopping app used Data lake in Amazon s3 to ease up their processes
- A market intelligence agency Similarweb used data lake to understand how customers are interacting with the website

Recent Posts
- Positive Vs. Negative Testing: Examples, Difference & ImportanceApril 22nd, 2024
- What Is Statement Coverage Testing? Explained With Examples!April 13th, 2024
- 60 Important Automation Testing Interview Questions & AnswersApril 2nd, 2024
- Verification vs. Validation: Key Differences and Why They MatterMarch 19th, 2024
- What is Compatibility Testing? Example Test Cases Included!March 18th, 2024

Search Results for:
Loading...
Overview
Services
Industries




Follow us on
Contact Us
Copyright © 2026 | Digital Marketing by Jointviews