

Blog Category
 Mobile App Testing(136)
Mobile App Testing(136) Web App Testing(11)
Web App Testing(11) Game Testing(24)
Game Testing(24)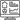 Automation Testing(73)
Automation Testing(73) Security Testing(32)
Security Testing(32) Performance Testing(15)
Performance Testing(15) Selenium(32)
Selenium(32) Test Management(15)
Test Management(15) Usability Testing(24)
Usability Testing(24) Guides and Tutorials(99)
Guides and Tutorials(99) Best Practices(28)
Best Practices(28) Expert Insights(20)
Expert Insights(20) Software Testing Events(4)
Software Testing Events(4)
Our Services
- App Testing(136)
- Web App Testing(11)
- Game Testing(24)
- Automation Testing(79)
 Load Testing(9)
Load Testing(9)- Security Testing(32)
 Performance Testing(15)
Performance Testing(15) Hire a Tester(71)
Hire a Tester(71)
Our Careers

What is Data Flow Testing? Application, Examples and Strategies
November 25th, 2023
Data Flow Testing, a nuanced approach within software testing, meticulously examines data variables and their values by leveraging the control flow graph. Classified as a white box and structural testing method, it focuses on monitoring data reception and utilization points.
This targeted strategy addresses gaps in path and branch testing, aiming to unveil bugs arising from incorrect usage of data variables or values—such as improper initialization in programming code. Dive deep into your code's data journey for a more robust and error-free software experience.
 (source)
(source)
Data Flow Testing Strategies
 Conclusion
One key tactic that becomes apparent is Data Flow Testing, which provides a deep comprehension of the ways in which data variables move through the complex circuits of software code.
This testing methodology enables developers to find anomalies, improve code quality, and create a more cooperative and user-focused development environment by closely monitoring the process from definition to usage.
Whether static or dynamic, Data Flow Testing's empathic lens enables thorough test coverage, effective debugging, and early bug detection—all of which contribute to the robustness and dependability of software systems. Accept the power of data flow testing to create software experiences that are intuitive for end users and to help you spot possible problems.
Conclusion
One key tactic that becomes apparent is Data Flow Testing, which provides a deep comprehension of the ways in which data variables move through the complex circuits of software code.
This testing methodology enables developers to find anomalies, improve code quality, and create a more cooperative and user-focused development environment by closely monitoring the process from definition to usage.
Whether static or dynamic, Data Flow Testing's empathic lens enables thorough test coverage, effective debugging, and early bug detection—all of which contribute to the robustness and dependability of software systems. Accept the power of data flow testing to create software experiences that are intuitive for end users and to help you spot possible problems.
(source)
What is Data Flow Testing?
Data flow testing is a white-box testing technique that examines the flow of data in a program. It focuses on the points where variables are defined and used and aims to identify and eliminate potential anomalies that could disrupt the flow of data, leading to program malfunctions or erroneous outputs.
Data flow testing operates on two distinct levels: static and dynamic.
Static data flow testing involves analyzing the source code without executing the program. It constructs a control flow graph, which represents the various paths of execution through the code. This graph is then analyzed to identify potential data flow anomalies, such as:
-
Definition-Use Anomalies: A variable is defined but never used, or vice versa.
-
Redundant Definitions: A variable is defined multiple times before being used.
-
Uninitialized Use: A variable is used before it has been assigned a value.
Dynamic data flow testing, on the other hand, involves executing the program and monitoring the actual flow of data values through variables. It can detect anomalies related to:
-
Data Corruption: A variable's value is modified unexpectedly, leading to incorrect program behavior.
-
Memory Leaks: Unnecessary memory allocations are not properly released, causing memory consumption to grow uncontrollably.
-
Invalid Data Manipulation: Data is manipulated in an unintended manner, resulting in erroneous calculations or outputs.
Here's a real-life example
def transfer_funds(sender_balance, recipient_balance, transfer_amount): #Data flow starts temp_sender_balance = sender_balance temp_recipient_balance = recipient_balance #Check if the sender has sufficient balance if temp_sender_balance >= transfer_amount: # Deduct the transfer amount from the sender's balance temp_sender_balance -= transfer_amount #Add the transfer amount to the recipient's balance temp_recipient_balance += transfer_amount # Data flow ends #Return the updated balances return temp_sender_balance, temp_recipient_balanceIn this example, data flow testing would focus on ensuring that the variables (temp_sender_balance, temp_recipient_balance, and transfer_amount) are correctly initialized, manipulated, and reflect the expected values after the fund transfer operation. It helps identify potential anomalies or defects in the data flow, ensuring the reliability of the fund transfer functionality.
 Steps Followed In Data Flow Testing
Steps Followed In Data Flow Testing
Step #1: Variable Identification
Identify the relevant variables in the program that represent the data flow. These variables are the ones that will be tracked throughout the testing process.
Step #2: Control Flow Graph (CFG) Construction
Develop a Control Flow Graph to visualize the flow of control and data within the program. The CFG will show the different paths that the program can take and how the data flow changes along each path.
Step #3: Data Flow Analysis
Conduct static data flow analysis by examining the paths of data variables through the program without executing it. This will help to identify potential problems with the way that the data is being used, such as variables being used before they have been initialized.
Step #4: Data Flow Anomaly Identification
Detect potential defects, known as data flow anomalies, arising from incorrect variable initialization or usage. These anomalies are the problems that the testing process is trying to find.
Step #5: Dynamic Data Flow Testing
Execute dynamic data flow testing to trace program paths from the source code, gaining insights into how data variables evolve during runtime. This will help to confirm that the data is being used correctly in the program.
Step #6: Test Case Design
Design test cases based on identified data flow paths, ensuring comprehensive coverage of potential data flow issues. These test cases will be used to test the program and make sure that the data flow problems have been fixed.
Step #7: Test Execution
Execute the designed test cases, actively monitoring data variables to validate their behavior during program execution. This will help to identify any remaining data flow problems.
Step #8: Anomaly Resolution
Address any anomalies or defects identified during the testing process. This will involve fixing the code to make sure that the data is being used correctly.
Step #9: Validation
Validate that the corrected program successfully mitigates data flow issues and operates as intended. This will help to ensure that the data flow problems have been fixed and that the program is working correctly.
Step #10: Documentation
Document the data flow testing process, including identified anomalies, resolutions, and validation results for future reference. This will help to ensure that the testing process can be repeated in the future and that the data flow problems do not recur.
Types of Data Flow Testing
Static Data Flow Testing
Static data flow testing delves into the source code without executing the program. It involves constructing a control flow graph (CFG), a visual representation of the different paths of execution through the code. This graph is then analyzed to identify potential data flow anomalies, such as:
-
Definition-Use Anomalies: A variable is defined but never used, or vice versa.
-
Redundant Definitions: A variable is defined multiple times before being used.
-
Uninitialized Use: A variable is used before it has been assigned a value.
-
Data Dependency Anomalies: A variable's value is modified in an unexpected manner, leading to incorrect program behavior.
Static data flow testing provides a cost-effective and efficient method for uncovering potential data flow issues early in the development cycle, reducing the risk of costly defects later on.
Real-Life Example: Static Data Flow Testing in Action
Consider a simple program that calculates the average of three numbers:
Python
x = int(input("Enter the first number: "))
y = int(input("Enter the second number: "))
average = (x + y) / 2
print("The average is:", average)Static data flow testing would reveal a potential anomaly, as the variable average is defined but never used. This indicates that the programmer may have intended to print average but mistakenly omitted it.
Dynamic Data Flow Testing
Dynamic data flow testing, on the other hand, involves executing the program and monitoring the actual flow of data values through variables. This hands-on approach complements static data flow testing by identifying anomalies that may not be apparent from mere code analysis. For instance, dynamic data flow testing can detect anomalies related to:
-
Data Corruption: A variable's value is modified unexpectedly, leading to incorrect program behavior.
-
Memory Leaks: Unnecessary memory allocations are not properly released, causing memory consumption to grow uncontrollably.
-
Invalid Data Manipulation: Data is manipulated in an unintended manner, resulting in erroneous calculations or outputs.
Dynamic data flow testing provides valuable insights into how data behaves during program execution, complementing the findings of static data flow testing.
Real-Life Example: Dynamic Data Flow Testing in Action
Consider a program that calculates the factorial of a number:
Python
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
print(factorial(5))
Dynamic data flow testing would identify an anomaly related to the recursive call to factorial(). If the input is a negative number, the recursion would continue indefinitely, leading to a stack overflow error. Static data flow testing, which only analyzes the code without executing it, would not pick up this anomaly.
Advantages of Data Flow Testing
Adding Data Flow Testing to your toolkit for software development offers several compassionate benefits that guarantee a more dependable and seamless experience for developers and end users alike. Early Bug Detection Data Flow Testing offers a helping hand by closely examining data variables at the very foundation, identifying bugs early on, and averting potential problems later on. Improved Code Quality As Data Flow Testing improves your code quality, welcome a coding experience rich with empathy. Find inefficiencies and strengthen the software's resilience while keeping a careful eye on the inconsistent use of data. Thorough Test Coverage: Data Flow Testing understands the importance of thorough test coverage. It thoroughly investigates all possible data variable paths, making sure to cover all bases to guarantee your software performs as intended under a variety of conditions. Enhanced Cooperation: Encourage a cooperative atmosphere in your development team. Data flow testing promotes teamwork and empathy by fostering insights and a common understanding of how data variables are woven throughout the code. User-Centric Approach Treat end users with empathy as you embark on your software development journey. Data Flow Testing guarantees a more seamless and user-centric experience by anticipating and resolving possible data problems early on, saving users from unanticipated disruptions. Effective Debugging Use the knowledge gathered from Data Flow Testing to enhance your debugging endeavors. With a compassionate eye, find anomalies to speed up and reduce the duration of the debugging process.Data Flow Testing Limitations/Disadvantages
Although data flow testing is an effective method for locating and removing possible software flaws, it is not without its drawbacks. The following are a few restrictions on data flow testing: Not every possible anomaly in data flow can be found every time. Static or dynamic analysis may not be able to identify certain anomalies due to their complexity. In these situations, testing might not catch every possible issue. Testing data flow can be costly and time-consuming. Data flow testing can significantly increase the time and expense of the development process, especially when combined with other testing techniques. This may be especially true when examining intricate and sizable systems. Not all software types can benefit from data flow testing. The best software for data-driven software is data flow tested. Data flow testing might not be as useful for software that is not data-driven. Testing for data flow issues might not be able to find every kind of flaw. Not every flaw has to do with data flow. Data flow testing might miss flaws pertaining to timing problems or logic errors, for instance. Other testing techniques should not be used in place of data flow testing. To provide a thorough evaluation of software quality, data flow testing should be combined with other testing techniques, like functional and performance testing.Data Flow Testing Coverage Metrics:
- All Definition Coverage: Encompassing "sub-paths" from each definition to some of their respective uses, this metric ensures a comprehensive examination of variable paths, fostering a deeper understanding of data flow within the code.
- All Definition-C Use Coverage: Extending the coverage spectrum, this metric explores "sub-paths" from each definition to all their respective C uses, providing a thorough analysis of how variables are consumed within the code.
- All Definition-P Use Coverage: Delving into precision, this metric focuses on "sub-paths" from each definition to all their respective P uses, ensuring a meticulous evaluation of data variable paths with an emphasis on precision.
- All Use Coverage: Breaking through type barriers, this metric covers "sub-paths" from each definition to every respective use, regardless of their types. It offers a holistic view of how data variables traverse through the code.
- All Definition Use Coverage: Elevating simplicity, this metric focuses on "simple sub-paths" from each definition to every respective use. It streamlines the coverage analysis, offering insights into fundamental data variable interactions within the code.
Data Flow Testing Strategies
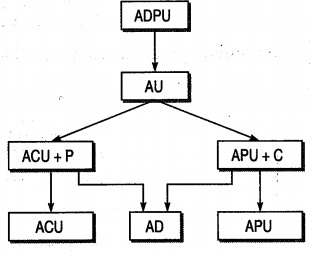
Test Selection Criteria: Guiding Your Testing Journey
To effectively harness the power of data flow testing, it's crucial to employ a set of test selection criteria that guide your testing endeavors. These criteria act as roadmaps, ensuring that your testing efforts cover a comprehensive range of scenarios and potential data flow issues.
All-Defs: Covering Every Definition
The All-Defs strategy takes a comprehensive approach, ensuring that for every variable and its defining node, all paths leading to potential usage points are explored. This strategy leaves no stone unturned, ensuring that every variable's journey is thoroughly examined.
All C-Uses: Unveiling Computational Usage
The All C-Uses strategy focuses on identifying and testing paths that lead to computational uses of variables. Computational uses, where variables are employed in calculations or manipulations, are critical areas to scrutinize, as they can harbor potential data flow anomalies.
All P-Uses: Uncovering Predicate Usage
The All P-Uses strategy shifts its focus to predicate uses, where variables are used in logical conditions or decision-making processes. Predicate uses play a pivotal role in program control flow, and ensuring their proper data flow is essential for program correctness.
All P-Uses/Some C-Uses: A Strategic Balance
The All P-Uses/Some C-Uses strategy strikes a balance between predicate and computational usage, focusing on all predicate uses and a subset of computational uses. This strategy provides a balance between coverage and efficiency, particularly when dealing with large or complex programs.
Some C-Uses: Prioritizing Critical Usage
The Some C-Uses strategy prioritizes critical computational uses, focusing on a subset of computational usage points deemed to be most susceptible to data flow anomalies. This strategy targets high-risk areas, maximizing the impact of testing efforts.
All C-Uses/Some P-Uses: Adapting to Usage Patterns
The All C-Uses/Some P-Uses strategy adapts to the usage patterns of variables, focusing on all computational uses and a subset of predicate uses. This strategy is particularly useful when computational uses are more prevalent than predicate uses.
Some P-Uses: Targeting Predicate-Driven Programs
The Some P-Uses strategy focuses on a subset of predicate uses, particularly suitable when predicate uses are the primary drivers of program behavior. This strategy is efficient for programs where predicate uses dictate the flow of data.
All Uses: A Comprehensive Symphony
The All Uses strategy encompasses both computational and predicate uses, providing the most comprehensive coverage of data flow paths. This strategy is ideal for critical applications where the highest level of assurance is required.
All DU-Paths: Unraveling Definition-Use Relationships
The All DU-Paths strategy delves into the intricate relationships between variable definitions and their usage points. It identifies all paths that lead from a variable's definition to all of its usage points, ensuring that the complete flow of data is thoroughly examined.
Conclusion
One key tactic that becomes apparent is Data Flow Testing, which provides a deep comprehension of the ways in which data variables move through the complex circuits of software code.
This testing methodology enables developers to find anomalies, improve code quality, and create a more cooperative and user-focused development environment by closely monitoring the process from definition to usage.
Whether static or dynamic, Data Flow Testing's empathic lens enables thorough test coverage, effective debugging, and early bug detection—all of which contribute to the robustness and dependability of software systems. Accept the power of data flow testing to create software experiences that are intuitive for end users and to help you spot possible problems.
Recent Posts
- Positive Vs. Negative Testing: Examples, Difference & ImportanceApril 22nd, 2024
- What Is Statement Coverage Testing? Explained With Examples!April 13th, 2024
- 60 Important Automation Testing Interview Questions & AnswersApril 2nd, 2024
- Verification vs. Validation: Key Differences and Why They MatterMarch 19th, 2024
- What is Compatibility Testing? Example Test Cases Included!March 18th, 2024

Search Results for:
Loading...
Overview
Services
Industries




Follow us on
Contact Us
Copyright © 2026 | Digital Marketing by Jointviews